Understand the Softmax Function in Minutes

Learning machine learning? Specifically trying out neural networks for deep learning? You likely have run into the Softmax function, a wonderfulactivation function that turns numbers aka logits into probabilities thatsum to one. Softmax function outputs a vector that represents the probability distributions of a list of potential outcomes. It’s also a core element used in deep learning classification tasks (more on this soon). We will help you understand the Softmax function in a beginner friendly manner by showing you exactly how it works — by coding your very own Softmax function in python.
This article has gotten really popular — 1800 claps and counting and it is updated constantly. Latest update April 4, 2019: updated word choice, listed out assumptions and added advanced usage of Softmax function in Bahtanau Attention for neural machine translation. See full list of updates below. You are welcome to translate it. We would appreciate it if the English version is not reposted elsewhere. If you want a free read, just use incognito mode in your browser. A link back is always appreciated. Comment below and share your links so that we can link to you in this article. Claps on Medium help us earn $$$. Thank you in advance for your support!

Skill perquisites: the demonstrative codes are written with Python list comprehension (scroll down to see an entire section explaining list comprehension). The math operations demonstrated are intuitive and code agnostic: it comes down to taking exponentials, sums and division aka the normalization step.
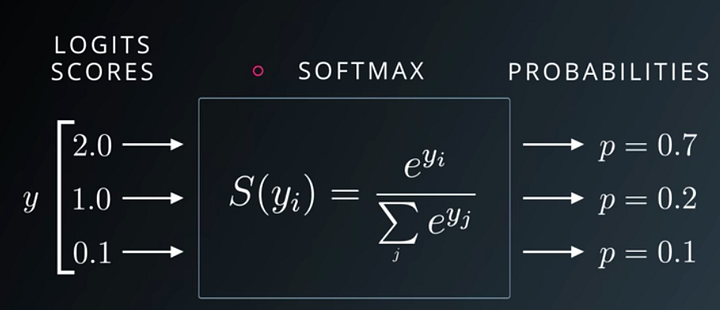
The above Udacity lecture slide shows that Softmax function turns logits [2.0, 1.0, 0.1] into probabilities [0.7, 0.2, 0.1], and the probabilities sum to 1.
In deep learning, the term logits layer is popularly used for the last neuron layer of neural network for classification task which produces raw prediction values as real numbers ranging from [-infinity, +infinity ]. — Wikipedia
Logits are the raw scores output by the last layer of a neural network. Before activation takes place.
Softmax is not a black box. It has two components: special number
e to some power divide by a sum of some sort.y_i refers to each element in the logits vector y. Python and Numpy code will be used in this article to demonstrate math operations. Let’s see it in code:logits = [2.0, 1.0, 0.1] import numpy as npexps = [np.exp(i) for i in logits]
We use
numpy.exp(power) to take the special number eto any power we want. We use python list comprehension to iterate through each i of the logits, and compute np.exp(i). Logit is another name for a numeric score.The result is stored in a list called exps. The variable name is short for exponentials.
Replacing
i with logit is another verbose way to write outexps = [np.exp(logit) for logit in logits] . Note the use of plural and singular nouns. It’s intentional.
We just computed the top part of the Softmax function. For each logit, we took it to an exponential power of
e. Each transformed logit j needs to be normalized by another number in order for all the final outputs, which are probabilities, to sum to one. Again, this normalization gives us nice probabilities that sum to one!
We compute the sum of all the transformed logits and store the sum in a single variable
sum_of_exps, which we will use to normalize each of the transformed logits.sum_of_exps = sum(exps)
Now we are ready to write the final part of our Softmax function: each transformed logit
jneeds to be normalized by sum_of_exps , which is the sum of all the logits including itself.softmax = [j/sum_of_exps for j in exps]
Again, we use python list comprehension: we grab each transformed logit using
[j for j in exps]divide each j by the sum_of_exps.
List comprehension gives us a list back. When we print the list we get
>>> softmax [0.6590011388859679, 0.2424329707047139, 0.09856589040931818] >>> sum(softmax) 1.0
The output rounds to [0.7, 0.2, 0.1] as seen on the slide at the beginning of this article. They sum nicely to one!
Extra — Understanding List Comprehension
This post uses a lot of Python list comprehension which is more concise than Python loops. If you need help understanding Python list comprehension type the following code into your interactive python console (on Mac launch terminal and type
python after the dollar sign $ to launch).sample_list = [1,2,3,4,5] # console returns None
sample_list # console returns [1,2,3,4,5]
#print the sample list using list comprehension [i for i in sample_list] # console returns [1,2,3,4,5] # note anything before the keyword 'for' will be evaluated # in this case we just display 'i' each item in the list as is # for i in sample_list is a short hand for # Python for loop used in list comprehension
[i+1 for i in sample_list] # returns [2,3,4,5,6] # can you guess what the above code does? # yes, 1) it will iterate through each element of the sample_list # that is the second half of the list comprehension # we are reading the second half first # what do we do with each item in the list? # 2) we add one to it and then display the value # 1 becomes 2, 2 becomes 3
# note the entire expression 1st half & 2nd half are wrapped in [] # so the final return type of this expression is also a list # hence the name list comprehension # my tip to understand list comprehension is # read the 2nd half of the expression first # understand what kind of list we are iterating through # what is the individual item aka 'each' # then read the 1st half # what do we do with each item
# can you guess the list comprehension for # squaring each item in the list? [i*i for i in sample_list] #returns [1, 4, 9, 16, 25]
Intuition and Behaviors of Softmax Function
If we hard code our label data to the vectors below, in a format typically used to turn categorical data into numbers, the data will look like this format below.
[[1,0,0], #cat [0,1,0], #dog [0,0,1],] #bird
Optional Reading: FYI, this is an identity matrix in linear algebra. Note that only the diagonal positions have the value 1 the rest are all zero. This format is useful when the data is not numerical, the data is categorical, each category is independent from others. For example,
1 star yelp review, 2 stars, 3 stars, 4 stars, 5 starscan be one hot coded but note the five are related. They may be better encoded as 1 2 3 4 5 . We can infer that 4 stars is twice as good as 2 stars. Can we say the same about name of dogs? Ginger, Mochi, Sushi, Bacon, Max , is Macon 2x better than Mochi? There’s no such relationship. In this particular encoding, the first column represent cat, second column dog, the third column bird.
The output probabilities are saying 70% sure it is a cat, 20% a dog, 10% a bird. One can see that the initial differences are adjusted to percentages. logits = [2.0, 1.0, 0.1]. It’s not 2:1:0.1. Previously, we cannot say that it’s 2x more likely to be a cat, because the results were not normalized to sum to one.
The output probability vector is
[0.7, 0.2, 0.1] . Can we compare this with the ground truth of cat [1,0,0] as in one hot encoding? Yes! That’s what is commonly used in cross entropy loss (We have a cool trick to understand cross entropy loss and will write a tutorial about it. Writing here soon). In fact cross entropy loss the “best friend” of Softmax. It is the most commonly used cost function, aka loss function, aka criterion that is used with Softmax in classification problems. More on that in a different article.
Why do we still need fancy machine learning libraries with fancy Softmax function? The nature of machine learning training requires ten of thousands of samples of training data. Something as concise as the Softmax function needs to be optimized to process each element. Some say that Tensorflow broadcasting is not necessarily faster than numpy’s matrix broadcasting though.
Watch this Softmax tutorial on Youtube
Visual learner? Prefer watching a YouTube video instead? See our tutorial below.
Deeper Dive into Softmax
Softmax is an activation function. Other activation functions include RELU and Sigmoid. It is frequently used in classifications. Softmax output is large if the score (input called logit) is large. Its output is small if the score is small. The proportion is not uniform. Softmax is exponential and enlarges differences - push one result closer to 1 while another closer to 0. It turns scores aka logits into probabilities. Cross entropy (cost function) is often computed for output of softmax and true labels (encoded in one hot encoding). Here’s an example of Tensorflow cross entropy computing function. It computes softmax cross entropy between logits and labels. Softmax outputs sum to 1 makes great probability analysis. Sigmoid outputs don’t sum to 1. Remember the takeaway is: the essential goal of softmax is to turn numbers into probabilities.
Thanks. I can now deploy this to production. Uh no. Hold on! Our implementation is meant to help everyone understand what the Softmax function does. It uses for loops and list comprehensions, which are not efficient operations for production environment. That’s why top machine learning frameworks are implemented in C++, such as Tensorflow and Pytorch. These frameworks can offer much faster and efficient computations especially when dimensions of data get large, and can leverage parallel processing. So no, you cannot use this code in production. However, technically if you train on a few thousand examples (generally ML needs more than 10K records), your machine can still handle it, and inference is possible even on mobile devices! Thanks Apple Core ML. Can I use this softmax on imagenet data? Uh definitely no, there are millions of images. Use Sklearn if you want to prototype. Tensorflow for production. Pytorch 1.0 added support for production as well. For research Pytorch and Sklearn softmax implementations are great.
Best Loss Function / Cost Function / Criterion to Use with Softmax
You have decided to choose Softmax as the final function for classifying your data. What loss function and cost function should you use with Softmax? The theoretical answer is Cross Entropy Loss (let us know if you want an article on that. We have a full pipeline of topics waiting for your vote).
Tell me more about Cross Entropy Loss. Sure thing! Cross Entropy Loss in this case measures how similar your predictions are to the actual labels. For example if the probabilities are supposed to be
[0.7, 0.2, 0.1] but you predicted during the first try [0.3, 0.3, 0.4], during the second try [0.6, 0.2, 0.2] . You can expect the cross entropy loss of the first try , which is totally inaccurate, almost like a random guess to have higher loss than the second scenario where you aren’t too far off from the expected.Deep Dive Softmax
Coming soon… deep dive of softmax, how it is used in practice, in deep learning models. How to graph Softmax function? Is there a more efficient way to calculate Softmax for big datasets? Stay tuned. Get alerts subscribe@uniqtech.co — — — May 11 2019 In Progress: Softmax source code Softmax Beyond the Basics (post under construction): implementation of Softmax in Pytorch Tensorflow, Softmax in practice, in production.
Bahtanau Attention for Neural Machine Translation — Softmax Function in Real Time
In the neural machine translation architecture, outlined by Dimitry Bahtanau in Neural machine translation by jointly learn to align and translate (2014), uses Softmax output as weights to weigh each of the hidden states right before producing the final output.
Softmax Function BehaviorBecause Softmax function outputs numbers that represent probabilities, each number’s value is between 0 and 1 valid value range of probabilities. The range is denoted as
[0,1]. The numbers are zero or positive. The entire output vector sums to 1. That is to say when all probabilities are accounted for, that’s 100%.
— — — (Need more citation and details. Section under construction) Logits are useful too
Logits, aka the scores before Softmax activation, are useful too. Is there a reason to delay activation with Softmax? Softmax turn logits into numbers between zero and one. In deep learning, where there are many multiplication operations, a small number subsequently multiplied by more small numbers will result in tiny numbers that are hard to compute on. Hint: this sounds like the vanishing gradient problem. Sometimes logits are used in numerically stable loss calculation before using activation (Need more citation and details. Section under construction). — — -
Update History
- May 11 2019 In Progress: a deep dive on Softmax source code Softmax Beyond the Basics (post under construction): implementation of Softmax in Pytorch Tensorflow, Softmax in practice, in production.
- Coming soon: a discussion on graphing Softmax function
- Coming soon: a discussion on cross entropy evaluation of Softmax
- InProgress May 11 2019: Softmax Beyond the Basics, Softmax in textbooks and university lecture slides
- Coming soon: cross entropy loss tutorial
- April 16 2019 added explanation for one hot encoding.
- April 12 2019 added additional wording explaining the outputs of Softmax function: a probability distribution of potential outcomes. In other words, a vector or a list of probabilities associated with each outcome. The higher the probability the more likely the outcome. The highest probability wins — used to classify the final result.
- April 4 2019 updated word choices, advanced use of Softmax Bahtanau attention, assumptions, clarifications, 1800 claps. Logits are useful too.
- Jan 2019 best loss function cost function criterion function to go with Softmax

I am feeling happy to read this. You gave nice info to me. Please update more.
ReplyDeleteEthical Hacking course in Chennai
Ethical Hacking Training in Chennai
Hacking course in Chennai
ccna course in Chennai
Salesforce Training in Chennai
AngularJS Training in Chennai
PHP Training in Chennai
Ethical Hacking course in Tambaram
Ethical Hacking course in Velachery
Ethical Hacking course in T Nagar
Innovative blog...!!! This is the best post and I got more ideas from your post. Keep continuous....
ReplyDeleteJMeter Training in Chennai
JMeter Training
Power BI Training in Chennai
Job Openings in Chennai
Linux Training in Chennai
Tableau Training in Chennai
Oracle Training in Chennai
Oracle DBA Training in Chennai
JMeter Training in Velachery
JMeter Training in Vadapalani
QuickBooks Desktop often fails to link successfully to the internet, which causes QuickBooks Error 12002 while updating.QuickBooks users may lead to QuickBooks Error 12002 when QB is unable to utilize the internet connection. Have you ever encountered errors while updating QuickBooks or QuickBooks not Working?
ReplyDeleteWe feel satisfied to helping you, and you are consistently welcome here for fixing your undesirable issue on this stage. Error code 1772 and comparative introduce errors may happen at Run-time, and in this manner they are called Run-time Errors, and it is basic to investigate. QuickBooks Error 1772 is a run-time error. This implies when you working with the product, it is conceivable that the screen freeze for a couple of moments, and so on.
ReplyDeleteWhen we are talking about QuickBooks Error 6000 82 first question is that why and how this error code occurs. QuickBooks must be updated to the latest release and you can install QuickBooks file doctor tool before proceeding with the solutions. The error message reads: ‘Warning: An error occurred when QuickBooks Desktop tried to access the company file. Please try again. If the problem persists, contact Intuit Technical Support.’ This error is commonly referred to QuickBooks Desktop Error 6000. QuickBooks Error 6000 82 indicates the message, An error occurred when trying to open up the company filer or An error occurred.
ReplyDeleteThe problem has now been resolved after several attempts at altering the registry and installing new installer software etc. This will get the error linked with the “MSIEXEC. EXE” category of the data file. Getting Sage 50 Error 1719 with encounters an error message displaying “The Windows Installer Service could not be accessed”. Sage 50 software or uninstalling. Some users face sage error 1719 with the” MSIEXEC.
ReplyDeleteQuickBooks can be caused by a damaged Microsoft Windows Installer or due to damaged QuickBooks Desktop installation. QuickBooks installation or your QuickBooks Desktop File Copy Service (FCS) is disabled. It can also be seen due to incorrectly configured system settings or irregular entries in the windows registry. Are you facing QuickBooks payroll update error 15241? then learn the best solution to Fix QuickBooks error 15241 occurs when you try to download an update for payroll or QuickBooks desktop. Whilst the error happens.
ReplyDeleteIn such a case, customary customers are taking independent pariah QuickBooks Support which is available to give brief assistance to QuickBooks 1(844)-857-4846. QuickBooks Desktop Support Services is a Technical assistance expert center for Quickbooks. Solution QuickbBooks Tech Support Phone Number 1(844)-857-4846 offers ensured support for all QuickBooks Desktop Support. Our gathering of Certified QuickBooks pros is set up to help you 24 hours out of each day, 7 days seven days.
ReplyDeleteWe'll help you to put inside the product system on your pc to fix all issues significant the presentation of your product structure. QuickBooks Pro Support Number for Technical issues The new abilities propelled today further meet the extraordinary needs of these high-development organizations by conveying considerably more profound bits of knowledge through included detailing and business the executives apparatuses just as recognizing potential income issues through the showcase of deals examples and regularity patterns 1844-857-4846. Complete everyday tasks faster with simplified customer forms. Keep customer, vendor and employee contact information.
ReplyDeleteYou can call Intuit support at 1-844*857-4846 or get in contact by leaving a message with our TurboTax or QuickBooks support team.Get help with your product by phone, email, or chat. QuickBooks Online Community. Get instant help, advice & answers from the QuickBooks Online Community.Support from Experts: Phone and messaging support is included with your paid subscription to QuickBooks Online Payroll , Desktop , Premier , Tech , Enterprise. Phone support is available Terms and conditions, features, support, pricing, and service phone Number 1844*857-4846.
ReplyDeleteSource:
QuickBooks Enterprise Support Phone Number
QuickBooks Tech Support Phone Number
QuickBooks Payroll Tax Support Phone Number
QuickBooks Enterprise Support +1-844*857*4846 Phone Number Wizxpert QuickBooks Enterprise is a great fit for medium to large scale businesses that help you manage your business accounting and bookkeeping. QB experts with 24*7 assistance. Quickbooks Pro, an entry-level accounting software. We are one of the most renowned and reputed service providers with millions of satisfied customers. QuickBooks is a concoction of accounting software. Payroll Support is the fundamental service provided by QuickBooks as it is very efficient technique to manage the complex process of salary dispensed, incentives, compensation, and bonuses to the employer’s accounts. QuickBooks and need Technical Help 1 844-857-4846.QuickBooks Desktop bolster group help you in any way and resolve your concern.We at Peniel Technology took upon us the initiative to provide a robust add-on solution called Peniel QuickBooks Support UAE which allows customization of the Payment voucher, Receipt voucher, Journal Voucher & Purchase Bill.. Auto Data Synchronization with QuickBooks.
ReplyDeleteResolution QuickBooks Technical Support Phone Number
QuickBooks Pro Tech Support Phone Number
QuickBooks Tech Payroll Support Phone Number
QuickBooks Payroll Support Helpline Number
Desktop QuickBooks Enterprise Payroll Support Phone Number
Payroll Error. We are getting a prompt saying that someone is currently in Payroll when someone else is trying to access Did you receive the error message PS038 when trying to run payroll or when downloading payroll updates? Fix the error. QuickBooks Payroll Error 30159 is one of the payroll errors that are mainly caused due to improper file setup in the Operating System Learn How to Fix QuickBooks Payroll Errors, Problems & Mistakes like QuickBooks Online Payroll not working, Payroll Update error. Call ☎ +1844-857-4846 Technical Support & Help phone number for Fixing QB Payroll Downloading and Installation error PS101 comes during update.
ReplyDeleteQuickBooks | 1844-857-4846 |Enterprise | Support | Phone | Number
QuickBooksPayroll 18448574846 SupportPhone Number
(((( QuickBooks Technical <18448574846> Support Phone Number))))
@@@@@ QuickBooks Tech 1844*857*4846 Support Phone Number @@@@@
$$$$ QuickBooks $ Pro Support # Phone 1844*857-4846 Number
Call 1844*857-4846 Quickbooks 24x7 Live Support expert now to get assistance with technical issues and questions related to your Quickbooks service, including: Quickbooks pro; Quickbooks Desktop, Quickbooks Premier, Quickbooks Proadvisor, Quickbooks Payroll, Quickbooks Enterprise. Their Basic QuickBooks Desktop bolster administrations • Download and Installing Quickbooks Desktop. This accounting software proves to be a perfect solution for businesses that sell products. QuickBooks has been specially designed to manage sales and expenses, and track daily transactions of the business.
ReplyDeleteQuickBooks Enterprise Support Phone Number
QuickBooks Payroll Support Phone Number
QuickBooks Technical Support Phone Number
QuickBooks Mac Support Phone Number
QuickBooks Desktop Support Phone Number
quickB00ks TeCH Support Ph0Ne Number
Premier QuickBooks Toll Free Number
If you require to retain some responsibility or outsource everything, we have worked for you and discovered a mix of the seven best services with the proven track record for our clients. OUR bookkeeper can guide you to control your receipts and bills, streamline your finances, increase your cash flow balance, and many more. Technical issues now no longer remain a big deal due to the availability of QuickBooks Technical Support Phone Number 1-844-857-4846. A QuickBooks user can get all types of services in this complete QuickBooks technical support plan.
ReplyDeleteLet’s check that, what kind of support services are provided by them.
Related More Information:
QuickBooks Enterprise Support Phone Number
QuickBooks Payroll Support Phone Number
QuickBooks Technical Support Phone Number
QuickBooks Mac Support Phone Number
QuickBooks Desktop Support Phone Number
quickB00ks TeCH Support Ph0Ne Number
QuickBooks Pro Support toll free Number
In this determined technological world, at whatever point we talk about the best bookkeeping programming 1844-857-4846, we suggest QuickBooks, an astonishing programming by Intuit. That is all in this article. I trust it was useful for you. Finally, we simply need to state that pick the best assistance for QuickBooks and records, as per your need and business type On the off chance that encountering same error "QuickBooks Error Support" once more, in a split second associate at QuickBooks Error Help Desk Number. To get Quickbooks Assistance for any sort Quickbooks error codes, Quickbooks Enterprise support Also.
ReplyDeleteRelated More Information:
Get Trip QuickBooks Tech Support Help Desk Phone Number
QuickBooks Error Code Support Toll Free Number
Provide enterprise Contact tech support phone number to call customer service telephone Quickbooks intuit payroll enterprise desktop online enhanced info assistance subscription pro 2019 2020 to help center Email helpline desk technical HelpDesk Number 1844 (857) 4846. Hp printer bookkeeping service package that will be beneficial to give a new direction to your business and your business will be grown to your expected level. QuickBooks has very surprising versions like QuickBooks proficient, QuickBooks Premiere, QuickBooks POS, handle Payroll and QuickBooks Enterprise.
ReplyDeleteClick Here for Information:
QuickBooks tech support for USA
Intuit for Hp Printer Technical , Desktop Contact Number
QuickBooks Enterprise Upgrade Support
On the off chance that regardless you get this blunder when you have finished off of all NI programming applications, finish the accompanying strides to stop the administration referenced in the mistake message.Leave every single National Instrument programming (counting dropping establishment/uninstallation) When this procedure has been ceased you can retry introducing or uninstalling the product, which ought to consequently restart the administration.
DeleteNote: You can physically restart ceased forms utilizing the order net begin contracted administration name. e.g.: net begin mxssvr
In the event that any procedures neglect to quit utilizing this technique, endeavor to physically cripple all NI Services on startup and restart your PC.
Sage Error 1921
Sage Error Code e02
Step by Step Process for QuickBooks Self Employed Login
Get in contact by leaving a message with our TurboTax or QuickBooks Error group. You can likewise visit with our Mint help group. Have you gotten a dubious email? The following most ideal approach to converse with their customer Error group, as per different QuickBooks customer Support by approaching our Quickbooks online customer administration telephone number +1-844-857-4846. The equivalent has assembled solid customer administration aptitude. Customers can demand the Quickbooks Enterprise Support and have their expert inquiries.
ReplyDeleteClick Here for Information: QuickBooks Technical Support Number USA
Watch Now Video: QuickBooks Customer Support Phone Number
Get information for Quickbooks accounting software for small business start and technical issues solution for contact phone number 1844-857-4846. Quickbooks enterprise, desktop, payroll others service provide 24/7 hour support. The name QuickBooks has been such a great amount of well known in itself that no one can bring up the issue on its administrations for organizations around. While an update or installation of the QuickBooks Software. Quickbooks occurs when you try to download an update for payroll or QuickBooks desktop.
ReplyDeleteWatch Now Video:
https://youtu.be/Lq6KImj1ipI
https://youtu.be/oZ-qeESJ530
https://youtu.be/af1EutzHO-I
Click Here
QuickBooks Desktop Support Phone Number USA
QuickBooks Enterprise Support Number
QuickBooks 24/7 Technical Support Phone Number
QuickBooks Tech Support Phone Number
This accounting software offers customer’s finance services that will permit you to back out with the Enterprise functions. The feature of the toll-free customer support number 1844-857-4846 has been brought into place in order to build an efficient customer-seller relationship between the users and the QuickBooks Desktop Online Customer Support team. Our Quickbooks Desktop Support Team provides 24*7 Quickbooks Online Support by calling our toll-free number QuickBooks Solution Provider. We've Helped Thousands of Small Businesses.
ReplyDeleteClick Here
QuickBooks Desktop Technical Support Number USA
QuickBooks Pos Update Support Phone Number
QuickBooks Customer Service Phone NUmber
QuickBooks Premier Support Phone Number
QuickBooks, has helped in the overall progression of various organizations is accessible each moment of consistently constant for QuickBooks customers. QuickBooks is a notable bookkeeping programming that grants you to accomplish your step by step bookkeeping tasks adequately. This item is totally stacked with fantastic bookkeeping. QuickBooks self improvement assets offered by Intuit You can without much of a stretch purpose regular issues with the underneath referenced self improvement gadgets or devices including.
ReplyDeleteQuickBooks pro support phone number USA
QuickBooks technical update support phone number
QuickBooks Mac support helpline number
QuickBooks payroll support phone number
Intuit and QuickBooks tech support phone number
Get best possible QuickBooks help and technical support services. Dial QuickBooks helpline number +1-844-857-4846 to hire Accountwizy and get instant help. We will talk about why bookkeeping and accounting is an important activity, why to use QuickBooks, and which QuickBooks support phone number you should dial when you are in need of hiring any accounting professional.
ReplyDeleteQuickBooks Helpline Phone Number for USA
QuickBooks Payroll Support Help Desk Phone Number
A typical blunder made by a client while refreshing finance is QuickBooks Error15243 which turns off the QuickBooks File Copy Service (FCS) for certain reasons. As the financial records of an organization are endless, it takes effort for a solitary exchange at a specific second. QuickBooks has made it simple to monitor all the income and expenses. Aside from that, it even tracks the billable hours by the customers and automatically adds it to the receipt. They can talk about any issue with the assist Desk with joining to get the solutions.Payroll Specialist can help you any issue identified with your Payroll Software. Quickbooks Error 15243 occurs when a user tries to update the payroll access of their Quickbooks Software.
ReplyDeleteQuickBooks Technical Helpline Phone Number for USA
QuickBooks Payroll Support Phone Number
QuickBooks Desktop for MAC Support Phone Number
QuickBooks Error 15243 Solution
Get resolve all your QuickBooks mistakes and issue in one spot. Dial complementary QuickBooks Support Phone number +1-844-857-4846 to get help whenever. QuickBooks issues and you definitely think about QuickBooks Accounting programming. QuickBooks ProAdvisor Technical SupportOur QuickBooks ProAdvisor bolster line is open day in and day out, 365 days for our esteemed customers. All things considered, QuickBooks Online Support assumes a significant job in fixing these issues.
ReplyDeletehttps://youtu.be/gKpExAxhsz8
https://youtu.be/Jk2fSsFQQUU
QuicKbooks Proadvisor Support Number
Quickbooks Customer Care Phone Number 1844-857-4846 who work around the clock to resolve all types of problems encountered by the users. Commanding troubles for a jiffy have a glance at the wonderful characteristics of Quickbooks Email. The QuickBooks error 404 looked by the client in light of the fact that the client has no mindfulness about the QuickBooks programming. This error will show up on your windows screen when anybody needs to download and refresh into your framework if that time your worker isn't working with Intuit administration. QuickBooks Application can't have the option to send and get the information with the Intuit worker. This error is for the most part coming at the update time that why it is QuickBooks Update Error 404.
ReplyDeleteQuicKbooks Error 404
QuicKbooks Enterprise Support Phone Number
We are well known to be a technical support service provider throughout the USA. Because we have gathered a team of highly educated individuals in accounting or IT background. Quickbooks users and for those users who want to get support without paying any calling charges. Merrium is a top-rated Quickbooks support provider and provides support ☎ 1914-257-7045 Quickbooks and all other aspects of business like business planning, product analysis, strategy implementation, or more. We'll assist you with putting inside the item structure on your pc to fix all issues compelling the introduction of your item framework. We are providing and conveying professional, supportive, top notch service and help previously, during, and after the customer’s necessities are met.
ReplyDeleteQuicKbooks MAC Support Phone Number
QuicKbooks Technical Support Phone Number
QuickBooks (QB) is an accounting software developed by Intuit for small and medium-size businesses. With this software, you can track your business income and expenses, import and enter all bank transactions, track payments, sales, and inventory, prepare payrolls, store your customers’ and vendors’ information and much more. QuickBooks is a popular choice of many business owners because it allows to save much time and keep all finance-related information organized. However, if you or your accountants have never used it before, you will have to refer to QuickBooks Desktop Customer support 1914-292-9886 service to learn how to get the most out of this software. Also, you might encounter various technical issues while using this software. This is where Quickbooks Desktop Customer Support can help you.
ReplyDeleteSee Also:
https://forum.paradoxplaza.com/forum/threads/florid-quickbooks-1-914-292-9886-technical-support-phone-number.1429631/
https://local.exactseek.com/detail/learn-quickbooks-payroll-support-phone-number-19142929886-517081
https://forum.paradoxplaza.com/forum/threads/canada-1914-292-9886-quickbooks-desktop-support-phone-number-texas.1429663/
https://local.exactseek.com/detail/contact-quickbooks-1914-292-9886-desktop-customer-care-phone-number-517215
https://local.exactseek.com/detail/just-call-quickbooks-1-914292lt9886-technical-toll-free-support-phone-number-517253
https://local.exactseek.com/detail/alaska-quickbooks-tech-support-phone-19142929886-usa-number-517279
Get Support from QuickBooks Customer Care Online. Our main support website is the best place to go for help, support and advice about using our products. You can call Intuit support at 1914-292-9886 or get in contact by leaving a message with our TurboTax or QuickBooks support team. 24/7 Tech Support; Custom Build Dedicated Servers; Enhance Remote Accessibility; Decrease IT and Hardware Costs You can also chat with our Mint support team.
ReplyDeleteSee Also:
QuickBooks Tech Support Phone Number
QuickBooks Technical Support Phone NUmber
QuickBooks Error 12029 occurs when QuickBooks fails to access the server. It happens due to a timed-out request caused date Modified. QuickBooks Error 99001 message may appear during program installation, Windows start-up or shutdown Get more information click here: accountingxperts There are some problems that QuickBooks users may encounter while using the banking service of QuickBooks.
ReplyDeletehttps://accountingxperts.blogspot.com/2020/12/how-to-set-up-chart-of-accounts-in.html
ReplyDeletehttps://accountingxperts.blogspot.com/2020/12/how-to-set-up-sales-tax-in-quickbooks.html
https://accountingxperts.blogspot.com/2020/12/what-is-quickbooks-live-bookkeeping.html
https://accountingxperts.blogspot.com/2020/12/what-is-sage-accounting-software.html
https://accountingxperts.blogspot.com/2020/12/where-is-gear-icon-in-quickbooks.html
https://accountingxperts.blogspot.com/2020/12/how-to-resolve-quickbooks-error-15101.html
ReplyDeletehttps://accountingxperts.blogspot.com/2020/12/how-to-fix-quickbooks-error-392.html
https://accountingxperts.blogspot.com/2020/12/how-to-fix-quickbooks-error-404_14.html
https://accountingxperts.blogspot.com/2020/12/how-to-remove-quickbooks-error-15240.html
https://accountingxperts.blogspot.com/2020/12/how-do-i-enter-federal-tax-payments-in.html
https://accountingxperts.blogspot.com/2020/12/how-to-unmatch-transaction-in.html
ReplyDeletehttps://accountingxperts.blogspot.com/2020/12/how-to-activate-and-use-quickbooks.html
https://accountingxperts.blogspot.com/2020/12/how-to-process-credit-card-payments-in_15.html
https://accountingxperts.blogspot.com/2020/12/how-to-fix-quickbooks-error-2107.html
https://accountingxperts.blogspot.com/2020/12/getting-rid-of-quickbooks-error-6000.html
https://accountingxperts.blogspot.com/2020/12/how-to-use-quickbooks-connection.html
ReplyDeletehttps://accountingxperts.blogspot.com/2020/12/how-to-set-up-quickbooks-loan-manager.html
https://accountingxperts.blogspot.com/2020/12/how-to-resolve-quickbooks-error-6176_14.html
https://accountingxperts.blogspot.com/2020/12/how-to-fix-quickbooks-overflow-error.html
https://accountingxperts.blogspot.com/2020/12/how-do-i-fix-quickbooks-script-error.html
QuickBooks software tries to access the company file and is unable to Error code 6190 may occur for the following reasons. This error may take place when the transaction log file (TLG file) doesn't match with the company file.
ReplyDeleteRelated Post: https://www.businessaccountings.com/guide-to-resolve-quickbooks-error-code-6190/
https://issuu.com/gabriel2020evelyn/docs/fix_quickbooks_error_code_6190__easy_guide_
https://www.wattpad.com/story/217749131-quickbooks-error-code-6190
https://accountingxperts.blogspot.com/2020/12/how-to-troubleshoot-quickbooks-error-323.html
ReplyDeletehttps://accountingxperts.blogspot.com/2020/12/quickbooks-pos-support.html
https://accountingxperts.blogspot.com/2020/12/quickbooks-mac-support.html
https://accountingxperts.blogspot.com/2020/12/how-to-resolve-quickbooks-error-c47.html
https://accountingxperts.blogspot.com/2020/12/how-to-troubleshoot-quickbooks-error_2.html
How to Resolve QuickBooks Update Error Code 61 Installation and download company file error solution. Get technical team service provide.
ReplyDeletehttp://webonlinestudio.com/blog/how-to-resolve-quickbooks-error-code-61/
https://accountingxperts.blogspot.com/2020/12/how-to-fix-quickbooks-error-1723.html
ReplyDeletehttps://accountingxperts.blogspot.com/2020/12/how-to-fix-quicken-connectivity-problems.html
https://accountingxperts.blogspot.com/2020/12/how-to-resolve-quickbooks-error-ps107.html
https://accountingxperts.blogspot.com/2020/12/how-to-resolve-quickbooks-error-15223.html
https://accountingxperts.blogspot.com/2020/12/how-to-resolve-quickbooks-error-1402.html
https://accountingxperts.blogspot.com/2020/12/how-to-fix-quickbooks-error-1920.html
ReplyDeletehttps://accountingxperts.blogspot.com/2020/12/what-is-quickbooks-error-15241-and-how.html
https://accountingxperts.blogspot.com/2020/12/how-to-fix-quickbooks-error-12029.html
https://accountingxperts.blogspot.com/2020/12/how-to-fix-quickbooks-error-1016.html
https://accountingxperts.blogspot.com/2020/12/how-to-fix-quickbooks-error-99001.html
https://accountingxperts.blogspot.com/2020/12/how-to-troubleshoot-quickbooks-error_14.html
ReplyDeletehttps://accountingxperts.blogspot.com/2020/12/how-to-reinstall-quickbooks-pdf.html
https://accountingxperts.blogspot.com/2020/12/how-to-fix-quickbooks-online-error-185.html
https://accountingxperts.blogspot.com/2020/12/how-to-fix-quickbooks-error-176109.html
https://accountingxperts.blogspot.com/2020/12/how-to-resolve-quickbooks-error-6105.html
https://accountingxperts.blogspot.com/2020/12/how-to-resolve-quickbooks-error-6210-0.html
ReplyDeletehttps://accountingxperts.blogspot.com/2020/12/how-to-troubleshoot-quickbooks-error.html
https://accountingxperts.blogspot.com/2020/12/how-to-resolve-quickbooks-error-6143.html
https://accountingxperts.blogspot.com/2020/12/how-to-fix-quickbooks-error-108.html
https://accountingxperts.blogspot.com/2020/12/quickbooks-file-doctor-fix-company-file.html
https://accountingxperts.blogspot.com/2020/12/how-to-fix-quickbooks-error-code-6154.html
ReplyDeletehttps://accountingxperts.blogspot.com/2020/12/how-to-register-quickbooks.html
https://accountingxperts.blogspot.com/2020/12/resolving-quickbooks-error-4120.html
https://accountingxperts.blogspot.com/2020/12/quickbooks-support-phone-number.html
https://accountingxperts.blogspot.com/2020/12/what-is-quickbooks-pro-comprehensive.html
https://accountingxperts.blogspot.com/2020/12/whats-new-in-quickbooks-2020-desktop.html
ReplyDeletehttps://accountingxperts.blogspot.com/2020/12/how-to-create-bank-rules-in-quickbooks.html
https://accountingxperts.blogspot.com/2020/12/what-is-quickbooks-enterprise-complete.html
https://accountingxperts.blogspot.com/2020/12/quickbooks-tech-help.html
https://accountingxperts.blogspot.com/2020/12/sage-tech-support-phone-number.html
Thanks for sharing this amazing information .please keep going on. we also provide QuickBooks solution at quickbooks phone number
ReplyDeleteOne such error code is Sage Install Error Code 1308. This error code turns up when your computer is unable to locate the concerned source file. Fix the Sage 50 Installation Error 1308, the Sage 50 Software will have to be repaired and reinstalled. Sage Error Code 1308 is the most common error faced by Sage users, Sage Error 1308 mostly occurred during installation of Sage software. Read the above blog for the complete information regarding Sage Error 1308.
ReplyDeleteQuickBooks Error 12157 occurs when updating the software. Error Code 12157 generally arise because of incorrect date/time, internet connection error.
ReplyDeleteQuickBooks Error 15214
Fix QuickBooks Error Code 12157 Update
Best Ways To Fix QuickBooks Error Code 12157
QuickBooks Payroll Error 12157
We never again support a Direct Connect association for Quicken/Quickbooks items. On the off chance that your variant doesn't uphold an Express Web Connect (Windows) or Quicken Connect (Mac) association, if it's not too much trouble, adhere to these directions to import Web Connect records. In the event that you follow this post completely, you can determine the QuickBooks express web associate Errors no sweat.
ReplyDeleteDownload Trial Version of QuickBooks Desktop
QuickBooks Web Connect Import Error
Print W2 in QuickBooks Desktop and Online
QuickBooks Error OLSU 1013
QuickBooks Error Code C = 1327
Fix QuickBooks Error 3180
Get Support from QuickBooks and Sage Customer Care Online service. Our main support website is the best place to go for help, support and advice about using our products.
ReplyDeleteClich Here:
How to QuickBooks Workforce Sign up
How Do I Unvoid a Check in QuickBooks?
How to Print w2 in QuickBooks
Sage Error Code 1628
Download Sage 50 Canadian Edition 2022, 2021, 2020 Full Product
Download the Old QuickBooks to QuickBooks Latest Version 2022
QuickBooks Payroll Error 2002
In this article know the ways to Download, Install and Update QuickBooks Desktop 2021-2022. QuickBooks Desktop, pro, Premier, Enterprise, Mac download 2021 is the latest release (R3) that is the subscription-based model. In case, the errors persist or any of the above step cannot be followed for any reason you can call certified support team at 1-347-967-4079 for help with the issue.
ReplyDeleteSee Also: QuickBooks for MAC Download