- Stop words removal
- Stop words are words that may not carry valuable information
- In some cases stop words matter. For example researchers found that stop words are useful in identifying negative reviews or recommendations. People use sentences such as "This is not what I want." "This may not be a good match." People may use stop words more in negative reviews. Researchers found this out by keeping the stop words and achieving better prediction results.
- Removing punctuation may also yield better results in some situations
- Tokenization : breaking texts into tokens. example: breaking sentences into words, and more group words based on scenarios. There's also the n gram model and skip gram model
- Basic tokenization is 1 gram, n gram or multi gram is useful when a phrase yields better result than one word, for example "I do not like Banana." one gram is I _space_ do _space_ not _space_ like _space_ banana. It may yield better result with 3 gram model: I do not, do not like, not like banana, like banana _space_, banana _space.
- ngram : n is the number of words we want in each token. Frequently, n =1
- Lemmatization: transform words into its roots. Example: economics, micro-economics, macro-economists, economists, economist, economy, economical, economic forum can all be transformed back to its root econ, which can mean this text or article is largely about economics, finance or economic issues. Useful in situations such as topic labeling. Common libraries: WordNetLemmatizer, Porter-Stemmer
- An illustration of sentence tagging
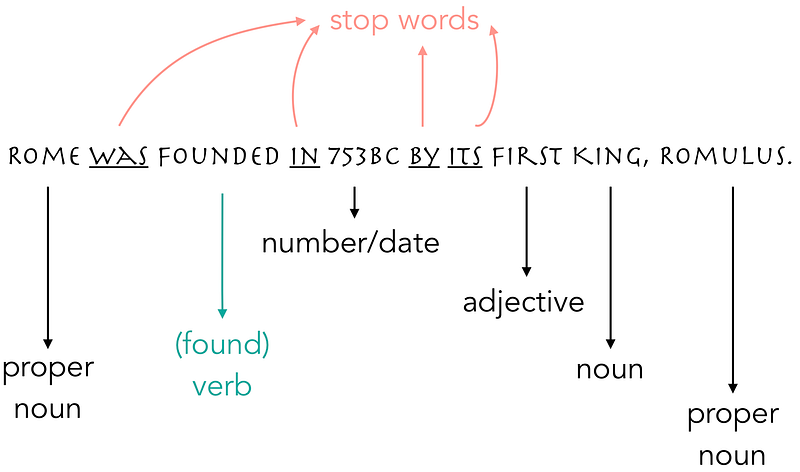 |
| Example of tokenization and lemmatization for ngrams = 1. source |
- Python library NLTK
- includes a list of stop words in English and many languages, you may want to customize this list
- Example The Sun and Sun mean different things, in certain analytics situation, it matters.
- from nltk.corpus import stopwords
- clean_tokens = [token for token in tokens if token not in stop_words] #important pattern
- source: Towards Data Science Emma Grimaldi How Machines understand our language: an introduction to Natural Language processing
- from nltk.tokenize import RegexpTokenizer a regex tokenization
- RegexpTokenizer(r'\w+') tokenize any word that has length > 1, effectively removing all punctuations
Sklearn Basics
- Sklearn text classification with sparse matrix http://scikit-learn.org/stable/auto_examples/text/document_classification_20newsgroups.html
- Read our article about TF-IDF model for information retrieval, document search read here
Count Vectorizer
What does it do? "Convert a collection of text documents to a matrix of token counts" (sklearn documentation). returns a sparse matrix scipy.sparse.csr_matrix
Feature Dimension : equal to the vocabulary size found by analyzing the data.
NLP Use Case
- Classify is a review positive or negative, sentiment analysis
