Natural Language Processing (NLP) is not supposed to be easy! But let’s try to simplify for beginners. Follow us for more beginner friendly articles like this.
Natural Language Processing or NLP is a subset of the field of Artificial Intelligence. It is a field that analyzes our human language, takes texts as input. The entire text dataset, the input data is called the corpus. For example we calculate how many times a word appears in the corpus. This count is called term frequency.
“Hi there! It’s good to see you. I just wanted to say hi.” # The sentence is the corpus. Term frequency of ‘hi’ is 2, because it appears twice in the corpus, if our analysis case insensitive (‘Hi’ equals to ‘hi’). If it is case sensitive, then the term frequency of ‘Hi’ is one, and TF of ‘hi’ is also one.
We will elaborate on term frequency later.
Practical tip: Sometimes it is important to be case sensitive. For example, Trump may refer to Donald Trump, trump is a verb often used in card games describing one card outranks another. When cases don’t matter, a common preprocessing, data cleaning technique is to change all text of the corpus to lower case. Lowering
lower_case_corpus = corpus.lower() The function .lower() is a python string method. For example “Hello there!” will become “hello there!”.Bag of Words — a common, introductory model for Natural Language Processing NLP
Codecademy.com explains bag-of-words model: “A bag-of-words model totals the frequencies of each word in a document, with each unique word being its own feature and its frequency being the value.”
If you haven’t studied Machine Learning the word feature makes no sense. There are tricks that may help you understand. We can imagine the output of a bag of word model as python dictionary / hashmap of key value pairs or as an Excel sheet. The features are the keys in the dictionary or the column headers in the Excel sheet. Features are meaningful representations of the data. Machine Learning learns features and predicts outcomes called labels.
For example useful features of Person data — information that describes people — may include: height, gender, name, government issued ID number etc.
Pro Tip: what is the feature dimension? What is the size or the number of features? It equals to the size of vocabulary found in the corpus.
corpus = ["You are reading a tutorial by Uniqtech. We are talking about Natural Language Processing aka NLP. Would you like to learn more? Learn more about Machine Learning today!"] # if use corpus = "..." # receive error # ValueError: Iterable over raw text documents expected, string object received.
from sklearn.feature_extraction.text import CountVectorizer count_vect = CountVectorizer() bow = count_vect.fit_transform(corpus) bow.shape #(1,22)
count_vect.get_feature_names() #[u'about', u'aka', u'are', u'by', u'language', u'learn', u'learning', u'like', u'machine', u'more', u'natural', u'nlp', u'processing', u'reading', u'talking', u'to', u'today', u'tutorial', u'uniqtech', u'we', u'would', u'you']
bow.toarray() #array([[2, 1, 2, 1, 1, 2, 1, 1, 1, 2, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 2]])
Pro tip: what does CountVectorizer do per the Sklearn documentation? “Convert a collection of text documents to a matrix of token counts” and returns a sparse matrix scipy.sparse.csr_matrix Just an FYI. Don’t think too hard about it now.
The feature names are returned by
count_vect.get_feature_names() and bow.toarray() gives us the frequency of corresponding features. For example, the first word ‘about’ appears twice in the corpus so its frequency is 2. The last word ‘you’ also appears twice.
How is it useful? This common model is surprisingly powerful. There are some criticism of the author of 50 Shades of Grey on the internet: the claim is that she is not a sophisticated author because her books only utilize limited English vocabulary. Apparently people have found that she uses some simple non-descriptive words too often, such as love and gasp. Below is a meme that makes fun of 50 Shades of Grey.
How did people know the author uses gasp a lot? Word count, word frequency of course!

If we read through this Word Frequency Analysis of the 50 Shades of Grey Trilogy, indeed we have to scroll down quite far to see a complex word that is also frequently used such as murmur.
Some argue however precisely because the author uses easy-to-read colloquial style the series has gained wide readership and popularity.
Surprisingly, this simple model is quite insightful and already generates a good discussion.
More on bag of words
Stop Word Removal … not : Not all words in the corpus are considered important enough to be features. Some such as a, the, and are called stop words, which are sometimes removed from the feature dataset to improve machine learning model results. The appeared nearly 5000 times in the bookbut it does not mean anything in particular, thus it’s okay to remove it from our dataset.
In the bag of words model, grammar does not matter so much, nor does word order.
Pro Tip: the bag-of-words model instance is often stored in a variable called
bow , which can be confusing because you may be thinking of bow and arrow, but it is the acronym for bag of words!]Sample natural language processing workflow and NLP pipeline:
Data cleaning pipeline for text data
- cleaning (regular expressions)
- sentence splitting
- change to lower case
- stopword removal (most frequent words in a language)
- stemming — demo porter stemmer
- POS tagging (part of speech) — demo
- noun chunking
- NER (name entity recognition) — demo opencalais
- deep parsing — try to “understand” text.
Important Natural Language Processing Concepts
Stop Words Removal
Stop words are words that may not carry valuable information.
In some cases stop words matter. For example researchers found that stop words are useful in identifying negative reviews or recommendations. People use sentences such as “This is not what I want.” “This may not be a good match.” People may use stop words more in negative reviews. Researchers found this out by keeping the stop words and achieving better prediction results.
While it is common practice to remove stop words and only returned clean text, removing stop words do not always give better prediction results. For example, not is considered in some NLP libraries, but not is a very significant word in negative reviews or recommendations in sentiment analysis. For example, if a customer states “I would not buy this product again, and would not accept any refund. Really not a good match at all.”, the word “not” is a strong signal that this review is negative. A positive review may sound, well, positive! “I really like the product! I enjoyed it very much. Not what I expected at all.” In this case, negative reviews use the “not” word 3x more.
Removing punctuation may also yield better results in some situations.
NLP Techniques — Removing punctuations with Regex
Punctuations are not always useful in predicting the meaning of texts. Often they are removed along with stop words. What does removing punctuation mean? It means keeping only the alpha numeric characters. Regex programming lessons can fill books! Just use this nifty function below for short texts. For longer texts that require more processing power, use iterable generators to iterate through each line of text and keep only alpha numeric characters. For big data, use parallel processing to process multiple lines of texts at once.
This process of removing numbers and punctuation is called pruning.
Regex removes punctuation
#import regex import re
corpus = "You are reading a tutorial by Uniqtech. We are talking about Natural Language Processing aka NLP. Would you like to learn more? Learn more about Machine Learning today!"
corpus = re.sub("[^a-zA-Z0-9]+", "",corpus)
corpus
# 'YouarereadingatutorialbyUniqtechWearetalkingaboutNaturalLanguageProcessingakaNLPWouldyouliketolearnmoreLearnmoreaboutMachineLearningtoday'
#note space is also removed
# ^\s means DO NOT MATCH SPACE
corpus = re.sub("[^a-zA-Z0-9\s]+", "",corpus)
corpus
#returns 'You are reading a tutorial by Uniqtech We are talking about Natural Language Processing aka NLP Would you like to learn more Learn more about Machine Learning today'
Go ahead, just use the above method and avoid reinventing the wheel.
Pro Tip: python also has a build in alpha numeric checker function
ialnum() . There is another .isalpha() only returns true for alphabets, a number will not evaluate to true.
There are always hackers coming up with fancy regex code! It keeps getting fancier.
from nltk.tokenize import RegexpTokenizer a regex tokenization RegexpTokenizer(r'\w+')
#tokenize any word that has length > 1, #effectively removing all punctuations
Tokenization
Tokenization: breaking texts into tokens. Example: breaking sentences into words, and more group words based on scenarios. There’s also the n gram model and skip gram model.
Basic tokenization is 1 gram, n gram or multi gram is useful when a phrase yields better result than one word, for example “I do not like Banana.” one gram is I _space_ do _space_ not _space_ like _space_ banana. It may yield better result with 3 gram model: I do not, do not like, not like banana, like banana _space_, banana _space.
ngram : n is the number of words we want in each token. Frequently, n =1
Did you know that Google digitized many books and generated and analyzed literature based on the n gram model? Nice work Google!
Lemmatization
Lemmatization: transforming words into its roots. Example: economics, micro-economics, macro-economists, economists, economist, economy, economical, economic forum can all be transformed back to its root econ, which can mean this text or article is largely about economics, finance or economic issues. Useful in situations such as topic labeling. Common libraries: WordNetLemmatizer, Porter-Stemmer.
Sentence Tagging
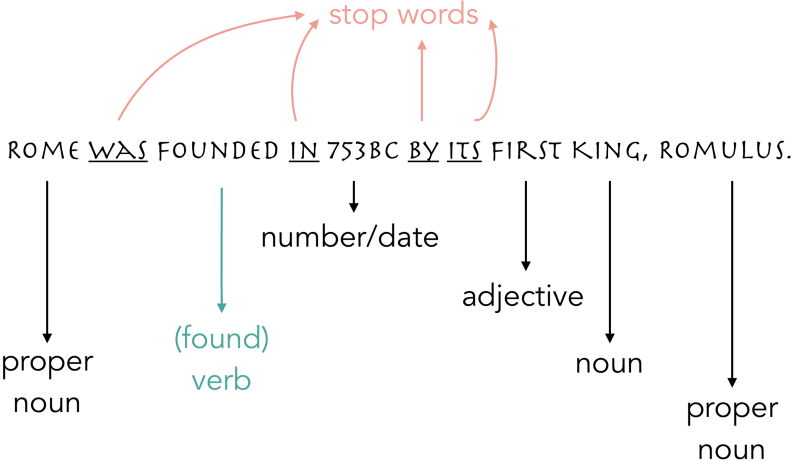
Sentence tagging is like the part of speech exercises your grammar teacher made you do in high school. Here’s an illustration of that:
Sections Coming soon…
To be notified, sign up here: subscribe@uniqtech.co
- Information Retrieval Basics : Term Frequency Inverse Document Frequency TFIDF
Shameless self plug below, please support us :)
Like what you read so far? Join our $5/month membership to get in-depth Silicon Valley job intelligence, beginner friendly tutorials, training courses for a tech career in Silicon Valley. subscribe@uniqtech.co
Our members only blog includes searchable in-depth analysis of Silicon Valley job postings such as Product Manager, Machine Learning Engineer. Information on tech interviews, technical interviews for bootcamp graduates. Tips and tricks to pass phone interviews. Our tutorials aim to be fast and beginner friendly. Check out our Medium article and Youtube video on Softmax — a function frequently used in Deep Learning, Artificial Intelligence and Machine Learning.
NLP Use Cases
- Sentiment analysis of tweets, amazon reviews. Classifying whether a short text is positive or negative.
- Writing style analysis analysis: authors’ favorite vocabulary choice, singers’ lyrics style. For example, style analysis has identified JK Rowling as the author of a book even though she used male a pen name after passionate readers analyzed and found parallels and similarity in the text styles.
- Entity tagging: find organizations or people’s names in articles
- Text summarization: summarize main points of news articles
Getting Started with NLP Now!
You can use the Python
nltk library to analyze texts. It’s a popular and a powerful library. It includes lists of stop words in several languages.from nltk.corpus import stopwords clean_tokens = [token for token in tokens if token not in stop_words]
#important pattern forremoving stop words iteratively
#source: Towards Data Science Emma Grimaldi How Machines understand our language
Sklearn conveniently has a build-in text dataset for you to experiment with! These news articles can be classified into different topics. Sklearn provides cleaned training data for this classification task.
Glossary
- SOS start of sentence
- EOS end of sentence
- padding usually 0
- word2index
- index2word
- word2count
Further Reading
- link to Sklearn documentation for CountVectorizer useful function to calculate term frequency
- link to a long list of Natural Language Processing NLP and Machine Learning papers
- link to Term Frequency Inverse Document Frequency blog post
- Towards Data Science Emma Grimaldi How Machines understand our language: an introduction to Natural Language processing
- Book — Natural Language Processing with PyTorch: Build Intelligent Language Applications Using Deep Learning

Certsout.com provides authentic IT Certification exams preparation material guaranteed to make you pass in the first attempt. Download instant free demo & begin preparation. 701-100 Exam Practice Test
ReplyDelete